


こんにちは、SaaS 事業部テックリードの丸山です。
私たち SaaS 事業部で取り扱っている商品のひとつに、動画配信プラットフォームの ULIZA があります。ULIZA は 2022 年 4 月に、ユーザーガイドや API 仕様書などのドキュメントを docs.p.uliza.jp にて一般公開しました(それまでは、ULIZA をご契約いただいたお客様だけに配布しておりました)。実はこのドキュメント、元々は PDF 形式だったのですが、今回ドキュメントを一般公開するのに合わせて HTML 形式への移植を行いました。本稿では、その経緯と移行方法についてご紹介したいと思います。
なお、この記事は前編と後編に分かれております。前編では VuePress を使用したドキュメントサイトの構築について紹介し、後編では OpenSearch を使用した全文検索機能の実装と CI/CD パイプラインの構築について紹介します。この記事は後編です。前編はこちら。
全文検索機能の実装
今回 HTML 形式への移植を行った主な目的のひとつは、ドキュメントの検索性を高めることでした。ドキュメントの本文が Markdown で記述されるようになったことで、全文検索エンジンへのドキュメントの取り込みが容易に行えるようになりました。ここからは、全文検索機能の実装を行なっていきます。
全文検索エンジンの選定
全文検索を行うための検索エンジンとしては、Elasticsearch を使用することにしました。理由は、おそらく全文検索エンジンとしては最も一般的であるため情報量が豊富であること、社内で既に使用されている実績があること、そして AWS によりマネージドサービスが提供されていることです。なお、現在 AWS マネージドの Elasticsearch は、Amazon OpenSearch Service として提供されています。
ところで、AWS が提供する検索サービスといえば、以下の 3 つが思い浮かびますね。
Amazon CloudSearch は、OpenSearch (Elasticsearch) と同様にドキュメントの全文検索を行うことができるサービスですが、OpenSearch よりも機能がシンプルになっており、細かいカスタマイズはできません。しかしながら、料金的には OpenSearch と比べて特に安いわけでもなく、また、こちらの リリースノート を見れば分かる通り、2017 年以降は積極的なリリースが行われておらず、新機能の開発はほぼ停止されていると言ってよいでしょう。そのため、採用は見送りました。
Amazon Kendra は、OpenSearch や CloudSearch とは異なり、機械学習を活用してユーザーが必要としている情報を回答するサービスです。こちらはウェブページや PDF ファイルなどを解析して自動でデータを収集することができる、とても賢いやつなのですが、その分料金は高めに設定されており、1 ヶ月あたり最低でも 810 USD かかります。ドキュメント検索にそこまでお金をかけたくなかったので、Amazon Kendra の採用は見送りました。
OpenSearch クラスタの作成
OpenSearch マネジメントコンソールから新規ドメイン(クラスタ)を作成しました。具体的な作成方法については、Web を検索すればすぐに見つかると思いますのでここでは割愛します。なお、本記事ではバージョンとして OpenSearch 1.0 の使用を前提としています。
同義語辞書の作成
ある事柄を検索するとき、大抵の場合はさまざまな言い換えが存在します。例えば、スマートフォンについて調べたいとき、「スマートフォン」「スマホ」「スマフォ」「モバイル」など、さまざまなキーワードで検索される可能性があります。「スマホ」と検索されても「スマートフォン」の記事が表示されるようにするためには、同義語辞書の作成が不可欠です。ここでは同義語辞書の作成方法について説明します。
まず、以下のように同義語をコンマ区切りで記述したテキストファイルを用意します。
synonyms.txt
スマートフォン,スマホ,スマフォ,モバイル コンピュータ,パソコン,PC ビデオ,映像,動画 オーディオ,音声,音楽 ミュート,消音
次に、このテキストファイルを任意の S3 バケットにアップロードします。
aws s3 cp synonyms.txt s3://example-bucket/synonyms.txt
続いて、OpenSearch のマネジメントコンソールからパッケージの登録を行います。マネジメントコンソールの Packages 画面を開き、[Import Package] をクリックします(筆者は管理画面の言語設定を英語にしています)。
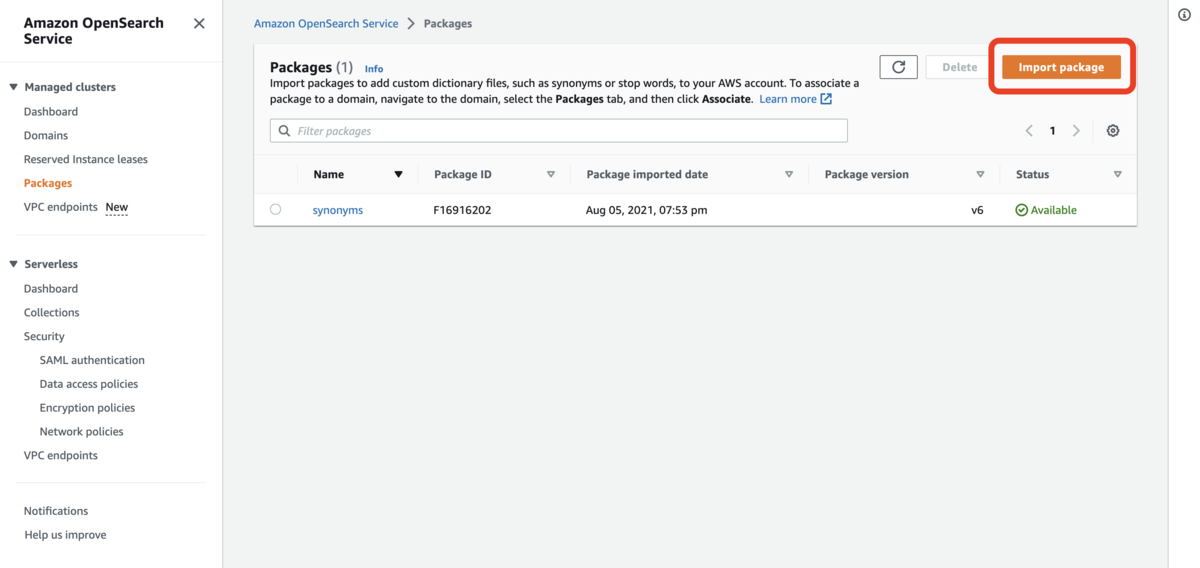
任意のパッケージ名と、先ほどアップロードしたファイルの S3 URI を指定して [Import] ボタンをクリックします。
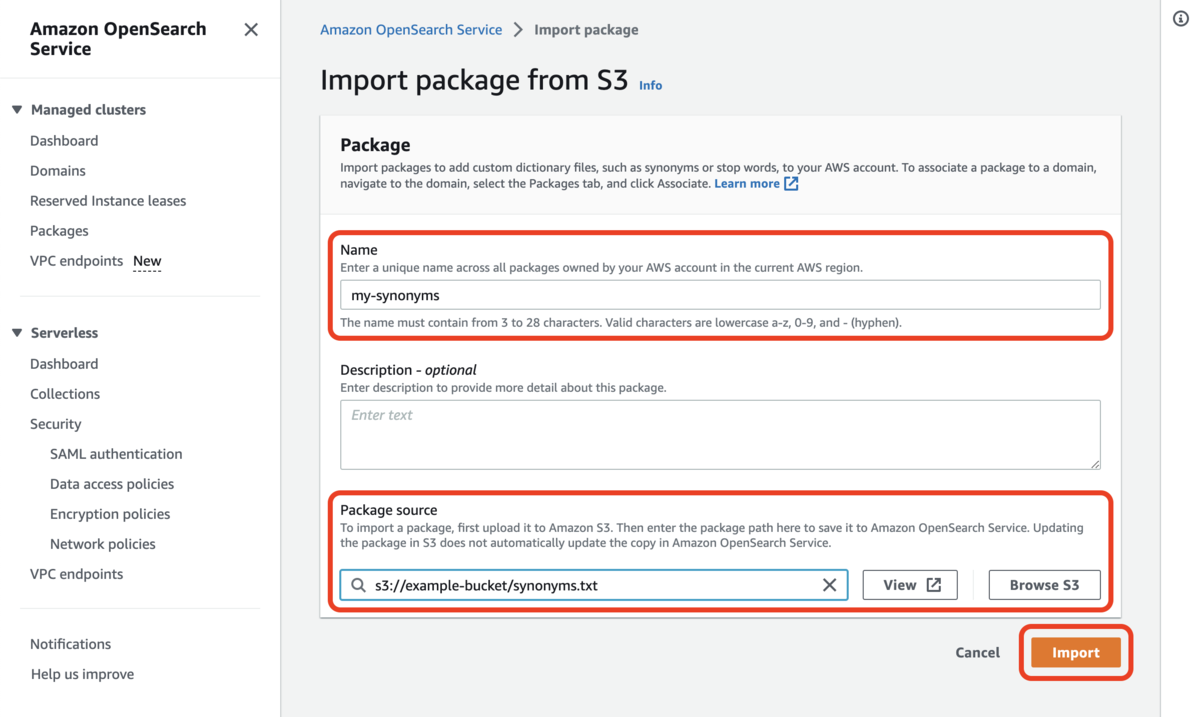
以上でパッケージが登録されました。続いて、パッケージをクラスタ(ドメイン)に紐付ける必要があります。紐づけたいドメインの詳細画面で Packages タブを開き [Associate package] ボタンをクリックします。
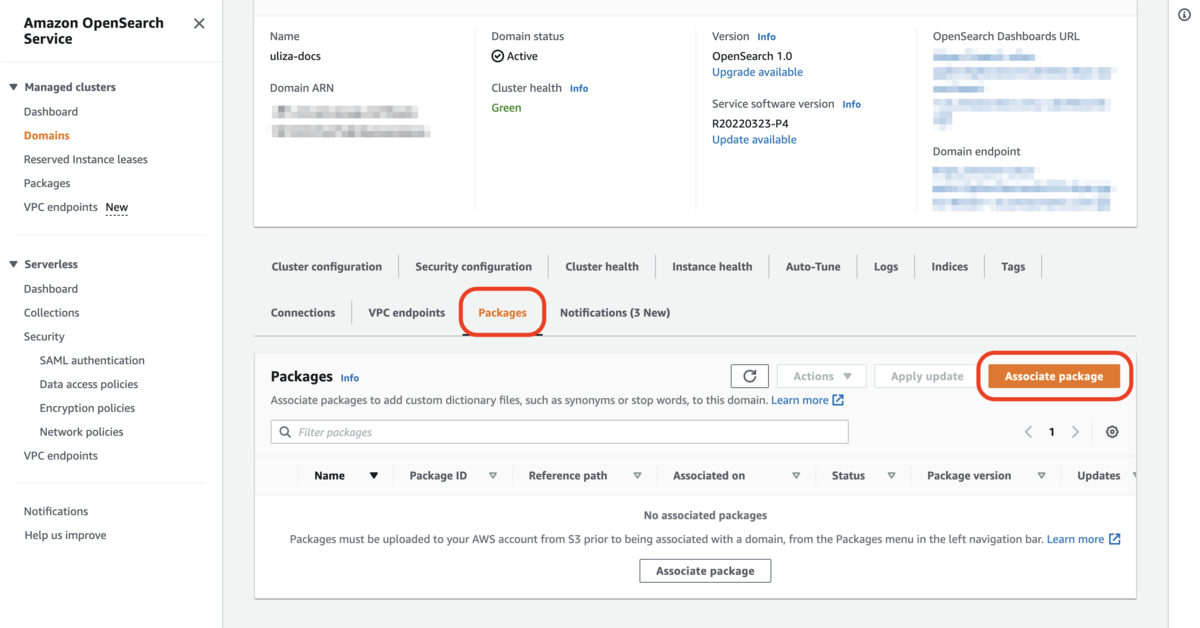
先ほどインポートしたパッケージを選択して [Associate] ボタンをクリックします。
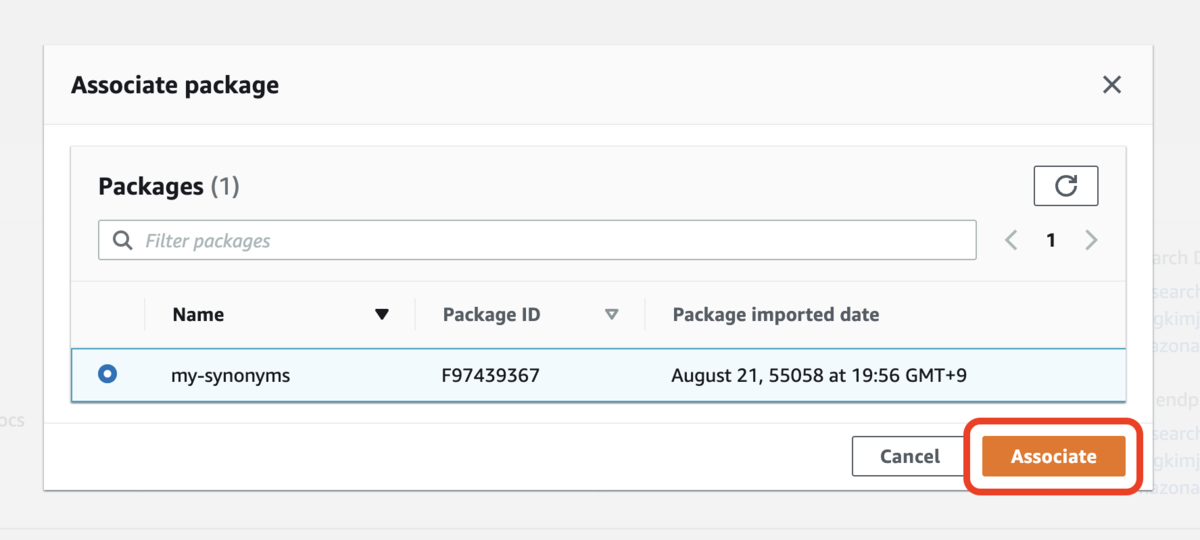
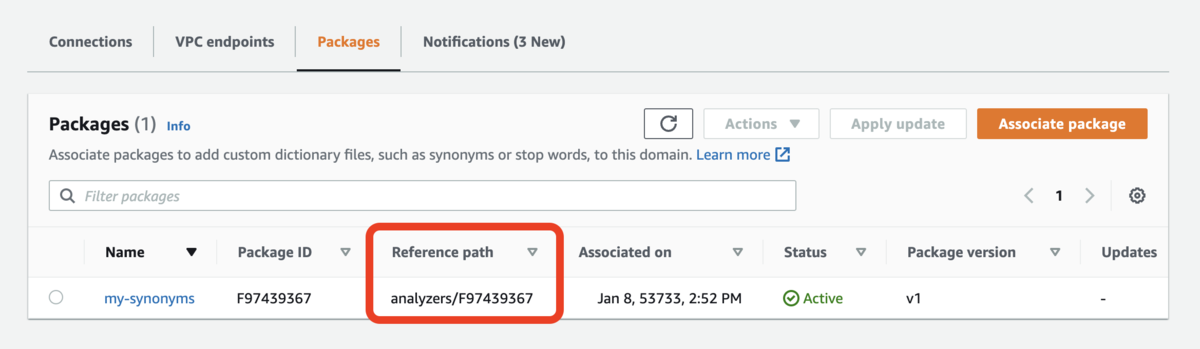
以上で、パッケージ(同義語辞書)をクラスタに紐づけることができました。紐付け完了後に表示される Reference path の値が、このあとに行うインデックスの作成時に必要となるので、メモしておきましょう。
インデックスの作成
ドキュメントのデータを格納するための「インデックス」を作成していきます。「インデックス」とは、RDBMS でいうところの「テーブル」に相当するもので、RDBMS における「インデックス」とは別の概念になります。
インデックスを作成するには、Create index API を使用します。OpenSearch の API をアドホックに実行したい場合は、OpenSearch Dashboards 内にある Dev Tools を利用するのがオススメです。
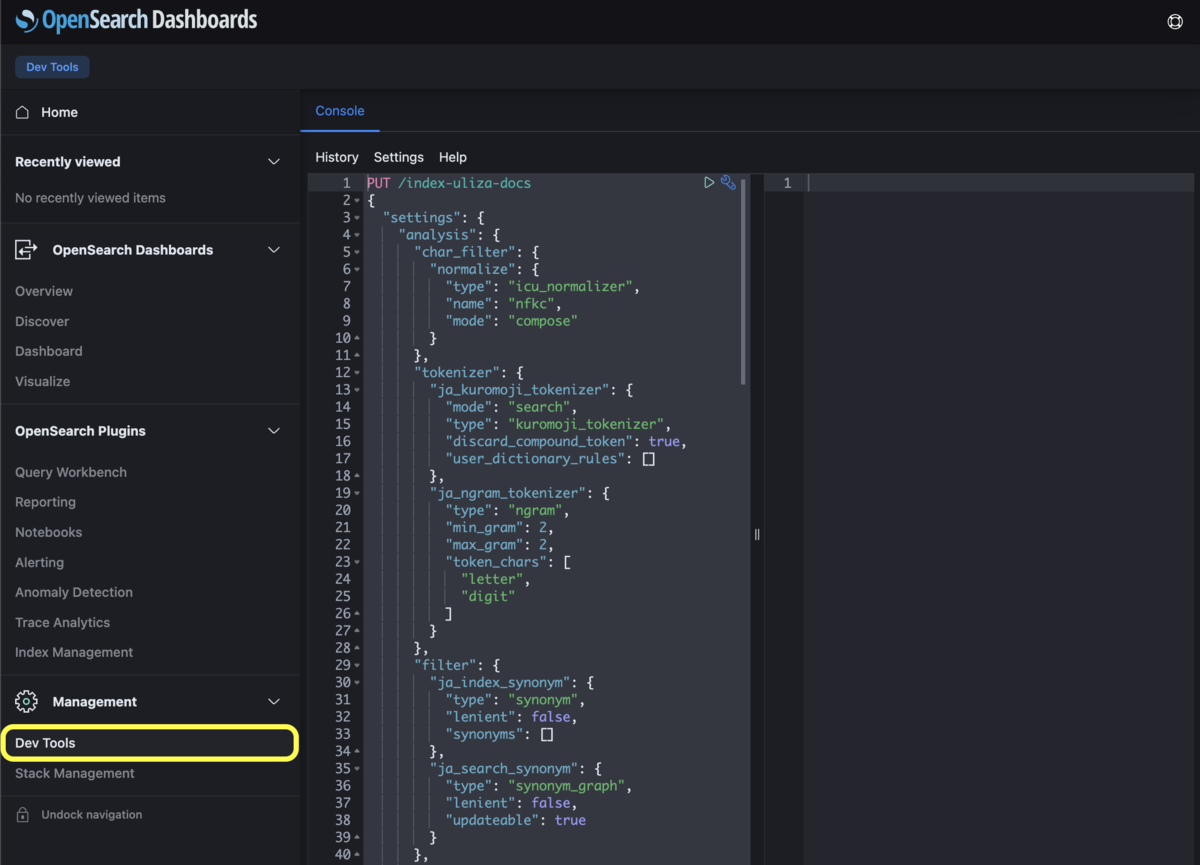
Dev Tools のコンソールに以下を入力したあと、「▶︎」ボタンをクリックして実行すると、インデックス(インデックス名:index-uliza-docs.2023-01-30)が作成されます。
PUT /index-uliza-docs.2023-01-30 { "settings": { "analysis": { "char_filter": { "normalize": { "type": "icu_normalizer", "name": "nfkc", "mode": "compose" } }, "tokenizer": { "ja_kuromoji_tokenizer": { "mode": "search", "type": "kuromoji_tokenizer", "discard_compound_token": true, "user_dictionary_rules": [] }, "ja_ngram_tokenizer": { "type": "ngram", "min_gram": 2, "max_gram": 2, "token_chars": [ "letter", "digit" ] } }, "filter": { "ja_index_synonym": { "type": "synonym", "lenient": false, "synonyms": [] }, "ja_search_synonym": { "type": "synonym_graph", "lenient": false, "synonyms_path": "analyzers/F97439367", "updateable": true } }, "analyzer": { "ja_kuromoji_index_analyzer": { "type": "custom", "char_filter": [ "normalize" ], "tokenizer": "ja_kuromoji_tokenizer", "filter": [ "kuromoji_baseform", "kuromoji_part_of_speech", "ja_index_synonym", "cjk_width", "ja_stop", "kuromoji_stemmer", "lowercase" ] }, "ja_kuromoji_search_analyzer": { "type": "custom", "char_filter": [ "normalize" ], "tokenizer": "ja_kuromoji_tokenizer", "filter": [ "kuromoji_baseform", "kuromoji_part_of_speech", "ja_search_synonym", "cjk_width", "ja_stop", "kuromoji_stemmer", "lowercase" ] }, "ja_ngram_index_analyzer": { "type": "custom", "char_filter": [ "normalize" ], "tokenizer": "ja_ngram_tokenizer", "filter": [ "lowercase" ] }, "ja_ngram_search_analyzer": { "type": "custom", "char_filter": [ "normalize" ], "tokenizer": "ja_ngram_tokenizer", "filter": [ "ja_search_synonym", "lowercase" ] } } } }, "mappings": { "properties": { "subject": { "type": "text", "search_analyzer": "ja_kuromoji_search_analyzer", "analyzer": "ja_kuromoji_index_analyzer", "term_vector": "with_positions_offsets", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 }, "ngram": { "type": "text", "search_analyzer": "ja_ngram_search_analyzer", "analyzer": "ja_ngram_index_analyzer" } } }, "content": { "type": "text", "search_analyzer": "ja_kuromoji_search_analyzer", "analyzer": "ja_kuromoji_index_analyzer", "term_vector": "with_positions_offsets", "fields": { "ngram": { "type": "text", "search_analyzer": "ja_ngram_search_analyzer", "analyzer": "ja_ngram_index_analyzer" } } } } } }
上記のインデックスの設定は、Elasticsearch の開発元である Elastic 社が公開している以下の記事を参考に設定しております。
HTTP PUT している JSON における各キーの設定内容について簡単に説明します。
| キー名 | 説明 |
|---|---|
| settings.analysis.char_filter | 入力文字列に適用するフィルタを定義しています。ここでは normalize という名前で、英数字やカタカナの全角/半角の表記揺れなどを吸収するフィルタを定義しています。このフィルタは後述するアナライザーの定義時に参照されます。 |
| settings.analysis.tokenizer | 入力文字列を分割するトークナイザーを定義しています。ここでは形態素解析を行い文字列を単語に分解する ja_kuromoji_tokenizer というトークナイザーと、n-gram 検索用の ja_ngram_tokenizer というトークナイザーを定義しています。これらは後述するアナライザーの定義時に参照されます。 |
| settings.analysis.filter | 入力データに適用するフィルタを定義しています。ここでは ja_index_synonym、ja_search_synonym という 2 つのフィルタを定義しています。synonym とは「同義語」という意味です。ja_search_synonym の synonyms_path に、あらかじめインポートしてあるパッケージの reference path を指定しています。また、updateable に true を指定することで、パッケージ(同義語辞書)の内容が更新されたときに自動的に検索結果に反映されるようにしています。なお、同義語の言い換えはインデクシング時に適用することも、検索時に適用することもできますが、インデクシング時に同義語を適用した場合、あとで辞書が更新されたとき、データを再インデクシングするまで反映されないので、ここでは検索時に適用するように設定しています(そのため ja_index_synonym の synonyms は空配列になっており、実際には機能していません)。 |
| settings.analysis.analyzer | 入力データに適用するアナライザを定義しています。インデクシング時と検索時のそれぞれについて、形態素解析用と n-gram 検索用で合計 2 x 2 = 4 個のアナライザが定義されています。 |
| mappings.properties | 検索対象となるデータに含まれる各プロパティに関する設定を行います。今回インデクシングするデータには subject(見出し)と content(本文)という 2 つのプロパティが含まれているため、それぞれについて設定を行います。 |
| mappings.properties.subject | subject(見出し)プロパティについて、検索時のアナライザには ja_kuromoji_search_analyzer を使用、インデクシング時のアナライザには ja_kuromoji_index_analyzer を使用するよう設定しています。また、fvh によるハイライト(検索結果表示時にキーワードとマッチしている部分を強調表示する機能)を使用するために、term_vector に with_positions_offsets を設定しています。また、このプロパティは完全一致と部分一致の両方で検索できるようにしておきたいので、multi-field(同じデータを複数の異なる手法で検索できるようにする機能)を使用して、fields.keyword という完全一致検索用のサブフィールドを定義しています。さらに、全文検索についても形態素解析による検索だけでなく n-gram 検索もできるようにするため、fields.ngram というサブフィールドも定義しています。 |
| mappings.properties.content | subject プロパティと同様の設定を行います。ただし、こちらのプロパティについては完全一致検索ができる必要はないので、fields.keyword サブフィールドは定義していません。 |
データのインデクシング
ドキュメントを検索できるようにするために、ドキュメントの内容を OpenSearch に登録(インデクシング)していきます。複数のデータを一括してインデクシングするためには、Bulk API を使用するのがよいでしょう。
インデクシングを始める前に、データをインデクシング可能な形式、具体的には JSON 形式に成形しておく必要があります。今回は、ドキュメントを「ページ単位」ではなく「段落単位」で検索できるようにしたいので、段落ごとに 1 個の JSON を作っていきます。
例えば、以下のような Markdown ドキュメントがあったとします。
# システム要件 この章では本製品のシステム要件について説明します。 ## 対応するファイル形式 本製品は配信形式として **HLS (HTTP Live Streaming)** をサポートします。 ## 推奨ブラウザ 本製品の管理画面は **Google Chrome** での操作を推奨します。
各見出し行(# から始まる行)から、その次の見出し行の直前までを 1 つの項目として、以下のように各項目をそれぞれ JSON 形式の文字列に成形します。これは Markdown 文字列を正規表現 /^#+/m で分割することなどによって比較的容易に実行できます。
{ "subject": "システム要件", "content": "この章では本製品のシステム要件について説明します。" } { "subject": "対応するファイル形式", "content": "本製品は配信形式として HLS (HTTP Live Streaming) をサポートします。" } { "subject": "推奨ブラウザ", "content": "本製品の管理画面は Google Chrome での操作を推奨します。" }
なお、本文部分に **テキスト** や |---|---| など Markdown 記法上の特殊記号が含まれる場合がありますが、全文検索においてこれらは不要ですので、実際には remove-markdown を使用して特殊記号を除去したものをインデクシングするようにしています。
実際にインデクシングするには、Bulk API の仕様に従い、実行したい操作を指示するためのメタデータ行を、各データ行の直前に挿入する必要があります。各データ行とメタデータ行の中には改行が含まれないように注意してください。最終的に、Bulk API のリクエストは以下のようになります。
POST /_bulk { "index": { "_id": "a5194d94-0e4a-4dc4-b452-c35a2badd72a" } } { "subject": "システム要件", "content": "この章では本製品のシステム要件について説明します。" } { "index": { "_id": "370f29a7-b080-4623-9f70-a9898e2af9df" } } { "subject": "対応するファイル形式", "content": "本製品は配信形式として HLS (HTTP Live Streaming) をサポートします。" } { "index": { "_id": "750f9caa-015c-4362-9f3f-e0569e45eaae" } } { "subject": "推奨ブラウザ", "content": "本製品の管理画面は Google Chrome での操作を推奨します。" }
エイリアスの設定
ドキュメントの内容は日々更新されていきます。元となるドキュメントの内容が更新されたら、OpenSearch にインデクシングしたデータも更新しなければなりません。OpenSearch にインデクシングされているデータを更新するためには、各データの ID を指定して Update document API を実行しなければなりません。そのためには、インデクシングしてある全てのデータの ID を管理しておく必要が出てきますし、データの個数だけ更新リクエストを実行するのは時間もかかります。
ULIZA では現在、ドキュメントごとにインデックスを分けてあります。そのため、ドキュメントの内容が更新されたら、そのドキュメントに紐づくインデックスを インデックスごと削除し、同名のインデックスを再作成してインデクシングすれば、各データを個別に更新する必要はなくなります。しかし、再インデクシングを行うのにも数分程度かかります。これではインデックスを削除してから再構築が完了するまでの間、検索結果に本来表示されるべき情報が表示されなくなってしまいます。
そこで、インデックスエイリアス 機能を活用しています。インデックスエイリアスを使うと、1 つまたは複数のインデックスに別名を与えることができます。インデックスエイリアスの参照先となるインデックスを切り替えることで、シームレスにデータの更新を行うことができます。
具体的な手順としては、まず新規インデックスを作成します。
PUT /index-uliza-docs.2023-01-30 { # インデックス設定は省略 }
次に、作成したインデックスにデータをインデクシングします。
POST /index-uliza-docs.2023-01-30/_bulk { "index": { "_id": "a5194d94-0e4a-4dc4-b452-c35a2badd72a" } } { "subject": "システム要件", "content": "この章では本製品のシステム要件について説明します。" } { "index": { "_id": "370f29a7-b080-4623-9f70-a9898e2af9df" } } { "subject": "対応するファイル形式", "content": "本製品は配信形式として HLS (HTTP Live Streaming) をサポートします。" } { "index": { "_id": "750f9caa-015c-4362-9f3f-e0569e45eaae" } } { "subject": "推奨ブラウザ", "content": "本製品の管理画面は Google Chrome での操作を推奨します。" }
最後に Create aliases API を実行してインデックスエイリアスを更新します。以下の例では、index-uliza-docs.current という名前のインデックスエイリアスを作成しています。名前が index-uliza-docs. から始まるすべてのインデックスを、インデックスエイリアスの参照先から削除したのち、新たな参照先として index-uliza-docs.2023-01-30 を追加しています。この追加と削除はアトミックに行われるため、一時的にエイリアスの参照先がなくなって検索できない、といった事態にはなりません。
POST /_aliases { "actions": [ { "remove": { "alias": "index-uliza-docs.current", "index": "index-uliza-docs.*" } }, { "add": { "alias": "index-uliza-docs.current", "index": "index-uliza-docs.2023-01-30" } } ] }
なお、どのエイリアスからも参照されなくなったインデックスは、不要なので定期的に削除しています(定期実行される Lambda 関数から Delete index API を実行しています)。
全文検索の実行
Search API を使用して全文検索を実行してみましょう。リクエストの URI は /<index-name>/_search ですが、<index-name> の部分にはワイルドカードを使用できます。以下のリクエスト例では、名前が .current で終わるインデックスおよびインデックスエイリアスに対して、横断的な検索のリクエストを行っています。
GET /*.current/_search { "query": { "simple_query_string": { "query": "検索したいキーワード", "fields": [ "subject^3", "content^3", "subject.ngram^1", "content.ngram^1" ], "default_operator": "AND" } }, "min_score": 0.5, "indices_boost": [ { "*user-guide*": 2.0 }, { "*release-note*": 0.5 } ], "highlight": { "order": "score", "encoder": "html", "fields": { "subject": { "no_match_size": 150, "number_of_fragments": 0, "matched_fields": [ "subject", "subject.ngram" ], "type": "fvh" }, "content": { "fragment_size": 150, "no_match_size": 150, "matched_fields": [ "content", "content.ngram" ], "type": "fvh" } } } }
JSON における各キーの設定内容について簡単に説明します。
| キー名 | 説明 |
|---|---|
| query.simple_query_string | 検索のキーワードを指定します。fields でどのフィールドを検索対象とするかを指定しています。ここでは subject(見出し)と content(本文)を検索対象としています。また、形態素解析と n-gram 検索を併用していますが、一般に n-gram 検索よりも形態素解析でのヒットのほうがマッチ度が高いため、形態素解析でのヒットがより検索結果で上位に表示されるよう、スコアを増加させています(^ の後ろの数字で重みを変化させています)。また、空白区切りで複数の単語を渡された場合は、AND 検索になるよう設定しています(デフォルトは OR 検索)。 |
| query.min_score | スコアの低い結果は返却しないよう、閾値を設定しています。 |
| query.indices_boost | 複数のインデックスにまたがる検索において、インデックスごとにスコアを増減させることができます。ULIZA ではドキュメントごとにインデックスを分けているのですが、「リリースノート」は新機能や不具合修正等を箇条書きにしたもので、お客様にとってより有益な情報が記載されているのは「ユーザーガイド」のほうになります。そのため、「ユーザーガイド」の検索結果がより上位に表示されるよう設定しています。 |
| query.highlight | キーワードとマッチしている部分を強調表示するために必要なハイライト情報を要求しています。これを指定すると、キーワードにマッチした部分が <em> 〜 </em> で囲まれた文字列が返却されるようになります。 |
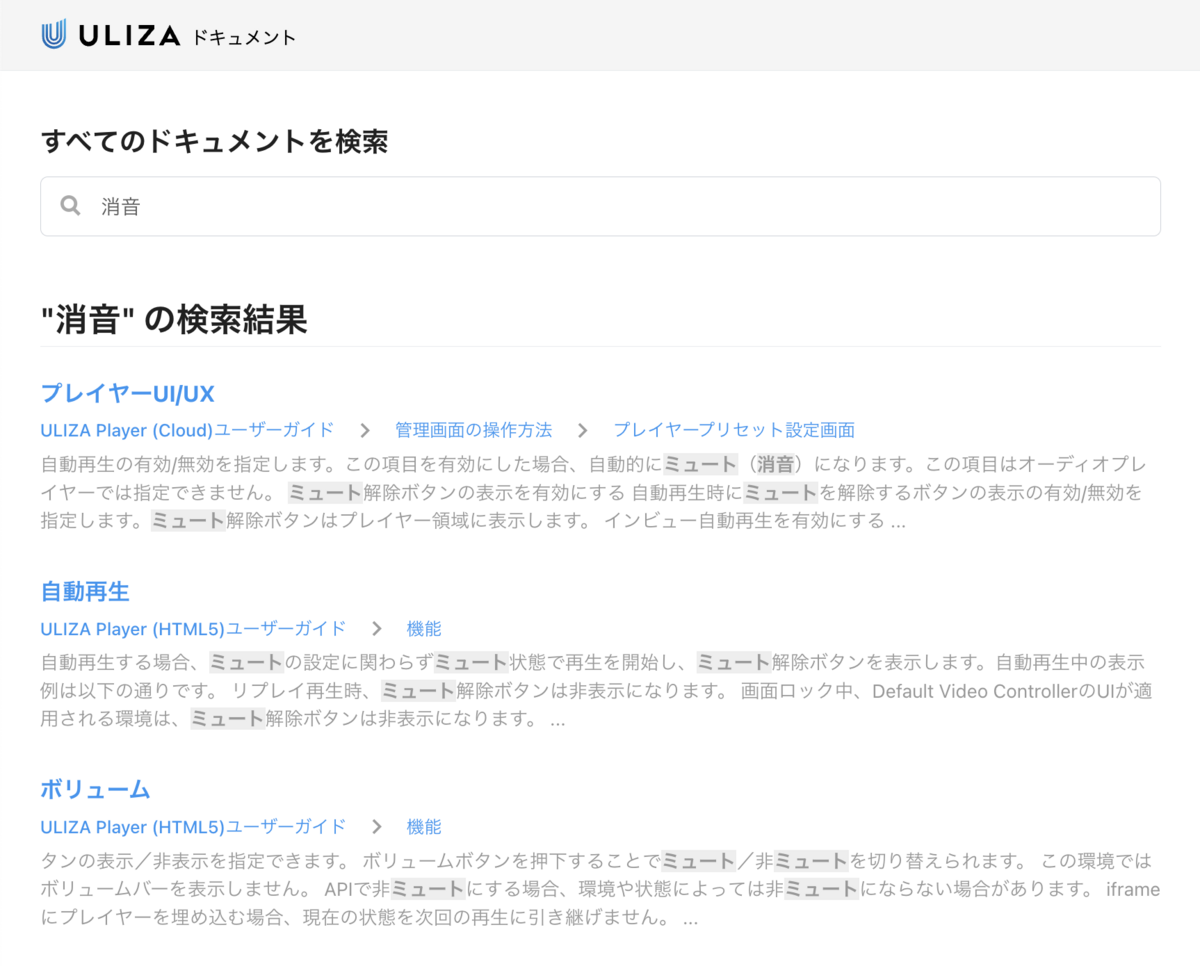
OpenSearch から返却されたクエリの結果をもとに、docs.p.uliza.jp では以下のように検索結果を表示しています。同義語辞書を設定しているため、「消音」というキーワードで検索しても「ミュート」という単語がハイライトされていることに注目してください。また、インデクシングをページ単位ではなく段落単位で行なっているため、検索結果も段落単位になります。各検索結果をクリックすると、ページ内リンクを使用して、該当のページの該当の段落位置まで自動でジャンプするようになっています。
CI/CD パイプラインの構築
ドキュメントに更新が発生した場合、以下の作業を実施する必要があります。
- ドキュメントサイトのビルド(
yarn run build) - ビルドして生成された静的ファイル(HTML, CSS 等)をサーバにアップロード
- OpenSearch インデックスの新規作成とデータのインデクシング
- インデックスエイリアスの参照先を新規インデックスに切り替え
これらの作業を簡略化するため、CI/CD パイプラインを構築して自動化しました。以下は CI/CD パイプラインを含む本システム全体の概略図になります(図中の矢印はデータがユーザーに届くまでの流れを表しています)。
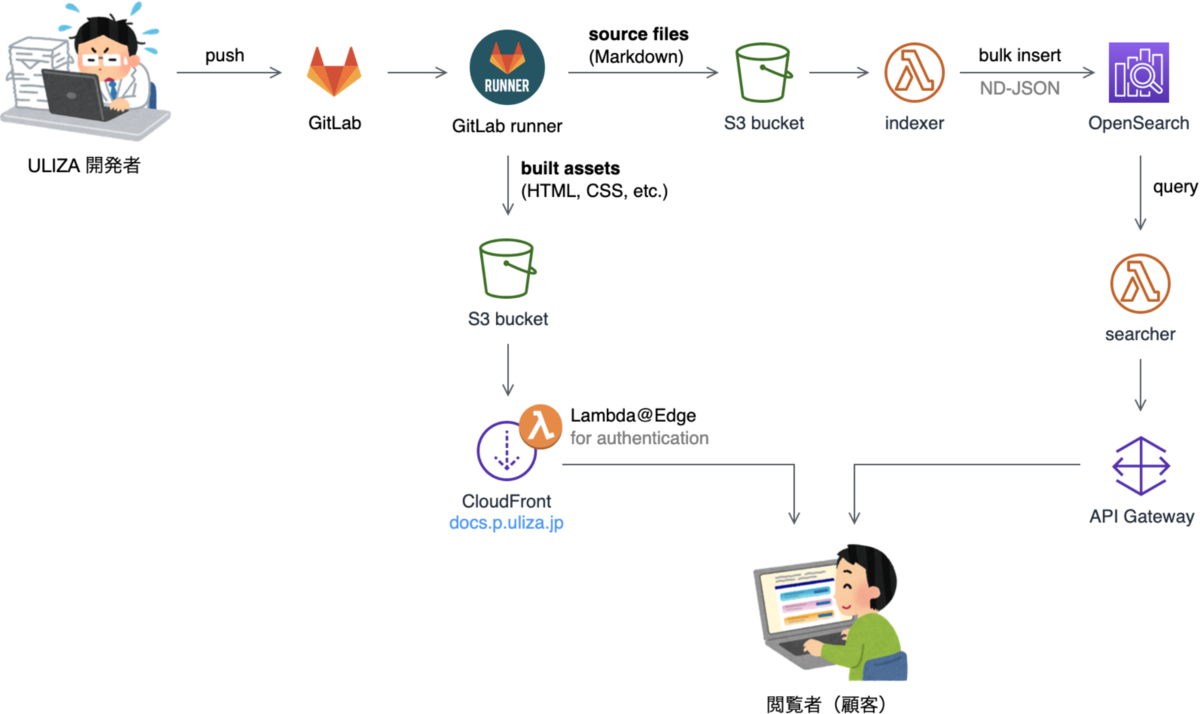
私たちのチームではソースコードの管理に GitLab を使用しています。開発者が GitLab にドキュメントを push すると、GitLab Runner が自動的に立ち上がります。GitLab Runner のコンテナ内では、主に以下の処理を実行しています。
- ドキュメントサイトのビルド(
yarn run build) - ビルドして生成された静的ファイルを S3 バケットにアップロード
- ソースコード(Markdown ファイル)を S3 バケットにアップロード
- Lambda 関数(indexer)の呼び出し
HTML, CSS 等はそのまま CloudFront を経由してインターネットに公開されます。indexer 関数は、S3 バケットから Markdown ファイルを取得して、Bulk API でインデクシング可能な状態(JSON 形式の文字列)に加工したのち、OpenSearch インデックスの新規作成とデータのインデクシング、インデックスエイリアスの参照先の切り替えを行っています。
おわりに
長くなりましたが、前編と後編を通して ULIZA のドキュメントサイトを PDF から HTML に移植して全文検索できるようにするまでの経緯と一連の工程について解説してきました。
このプロジェクトを実現したことで、ユーザーが必要な情報により速くアクセスできるようになりました。これにより、ULIZA をご契約いただいているお客様はもちろんのこと、私たち開発者や社内のプロダクトサポート/セールスのメンバーにとっても、プロダクトの細かい機能や API 仕様をすぐに調べることができるようになり、とても重宝しています。
また、今回このプロジェクトに取り組む上で、初めて全文検索エンジンというものを本格的に触ることになり、Elasticsearch や OpenSearch の基本的な使い方や性質について学ぶことができました。検索機能は奥が深く、ユーザーが知りたいと思っている情報をピンポイントで返せるようにするには、色々とチューニングを行う必要があります。今後も継続的に検索精度の向上と情報の充実化に取り組んでいきたいと思います。