


こんにちは、ソリューション技術部の藤原です。
弊社ではAWSでGitHub Enterprise Serverを運用しているのですが、監査等のためログを一定期間保存するようにしています。
今回はGitHub Enterprise ServerのsyslogをLogstashを使ってS3に保存し、Athenaで確認できるようにするまでの方法を紹介します。
GitHub以外でも、ログ取り込み・確認の参考になれば幸いです。
また今回は手動での設定方法をご紹介しますが、CloudFormationでの構築も可能かと思います。
前提事項
- GitHub Enterprise Serverは構築済みであること
- ログ転送サーバ(Logstash)のEC2はAmazon Linux 2023を想定
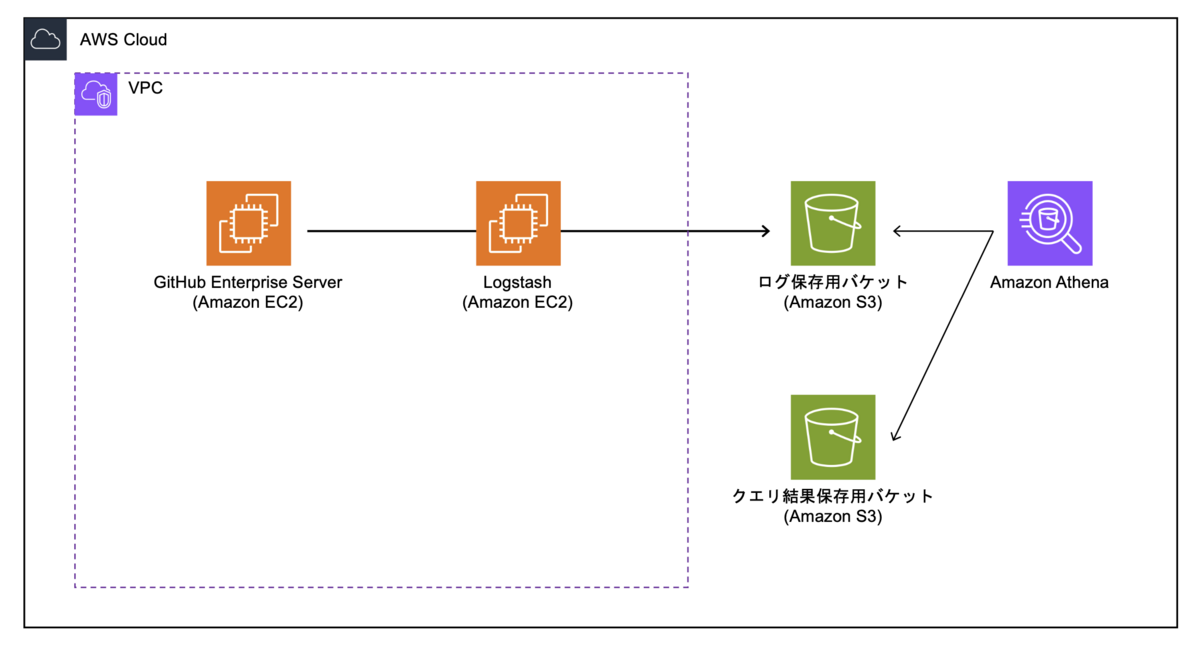
構成図
主な構成はGitHubサーバ(EC2)、ログ転送サーバ(EC2)、S3、Athenaです。
GitHub Enterprise Serverにはログを転送する機能が備わっているので、それをLogstashで受け取ってS3に保存していきます。
環境構築
まずはログ転送の環境構築です。 ログ転送用のEC2とログ保存用S3バケットの構築、GitHubでの転送設定をします。
IAMロール作成
EC2にアタッチするIAMロールを作成します。
後ほど作成するS3バケットポリシーでこのIAMロールのみPutを許可するようにします。
① AWSマネジメントコンソールでIAMを開きます。
② ロールを作成する際、「ユースケース」でEC2を選択します。
③ ポリシーは任意のものを選択してロールを作成します。
④ AWSへアクセス可能なターミナルで、作成したIAMロールのIDを確認します。
# aws iam get-role --role-name [IAMロール名] --output json | grep RoleId
"RoleId": "AROAXXXXXXXXXXXXXX",
S3ログ保存用バケット作成
ログを保存するバケットを作成します。
① AWSマネジメントコンソールでS3のバケットを作成します。
② 作成したバケットを選択してバケットポリシーを編集します。これは作成したIAMロールに対してのみPutの許可をするためのものです。
{ "Version": "2012-10-17", "Id": "PolicyXXXXXXX", "Statement": [ { "Effect": "Deny", "Principal": "*", "Action": "s3:Put*", "Resource": "arn:aws:s3:::[バケット名]/*", "Condition": { "StringNotLike": { "aws:userId": "[IAMロールID]:*" } } }, { "Effect": "Allow", "Principal": "*", "Action": [ "s3:Put*", "s3:List*" ], "Resource": [ "arn:aws:s3:::[バケット名]", "arn:aws:s3:::[バケット名]/*" ], "Condition": { "StringLike": { "aws:userId": "[IAMロールID]:*" } } } ] }
ログ転送用EC2構築
ログ転送サーバーを構築します。
① 新しくEC2を起動し、基本設定をします。
② EC2に作成したIAMロールをアタッチします。
③ EC2へSSHして、S3バケットへのアクセスとアップロードが出来ることを確認します。
# aws s3 ls s3://[バケット名] エラーが出ないこと # touch ./test # aws s3 cp test s3://[バケット名]/ testファイルがアップロードされていること 確認できたらtestファイルを削除しておく
④ Logstashをインストールします。
# yum install java-17-amazon-corretto
# java -version
openjdk version "17.0.8.1" 2023-08-22 LTS
OpenJDK Runtime Environment Corretto-17.0.8.8.1 (build 17.0.8.1+8-LTS)
OpenJDK 64-Bit Server VM Corretto-17.0.8.8.1 (build 17.0.8.1+8-LTS, mixed mode, sharing)
# rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
# vi /etc/yum.repos.d/logstash.repo
[logstash-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum install logstash
# systemctl enable logstash
# cp -p /etc/logstash/logstash-sample.conf /etc/logstash/conf.d/logstash.conf
# vi /etc/logstash/conf.d/logstash.conf
## beats→udpへ変更
## 5044→514へ変更(GitHubのsyslogが514ポートへ送信されるため)
## その他prefixなどの設定は任意
input {
udp {
port => 514
}
}
output {
s3 {
region => "ap-northeast-1"
bucket => "[バケット名]"
prefix => "%{+YYYY}/%{+MM}/%{+dd}"
encoding => "gzip"
}
}
# vi /etc/systemd/system/multi-user.target.wants/logstash.service
## User、Groupをrootへ変更
#User=logstash
#Group=logstash
User=root
Group=root
# systemctl daemon-reload
# systemctl start logstash
# systemctl status logstash
● logstash.service - logstash
Loaded: loaded (/usr/lib/systemd/system/logstash.service; enabled; preset: disabled)
Active: active (running) since
GitHubログ転送設定
GitHubの管理画面からログ転送設定をします。
① GitHub管理画面へログインします。
②「Site admin」から「Management Console」へ遷移します。
③「Enable log forwarding」にチェックします。
④ ログ転送サーバとプロトコルを設定します。
Server address:172.XX.XX.XX
(今回はGitHubとログ転送サーバーを同VPC内に構築したためプライベートIPで通信させるようにしました)
Protocol:UDP
※ オプション設定として「Enable TLS」など必要に応じて設定する
⑤ しばらくして、S3バケットにログファイルが追加されていくことを確認します。
ログ確認
Athenaでクエリ実行の準備をして、実際にログを確認してみます。
S3クエリ結果保存用バケット作成
① AWSマネジメントコンソールでAthenaのクエリ結果を保存するS3バケットを作成します。
Athena設定
① AWSマネジメントコンソールでAthenaのクエリエディタを起動します。
②「設定」タブ →「管理」へと遷移します。
③ クエリ結果の場所「S3を参照」から作成したバケットを選択し保存します。
④「エディタ」タブでクエリを実行し、Databaseを作成します。
CREATE DATABASE [データベース名]
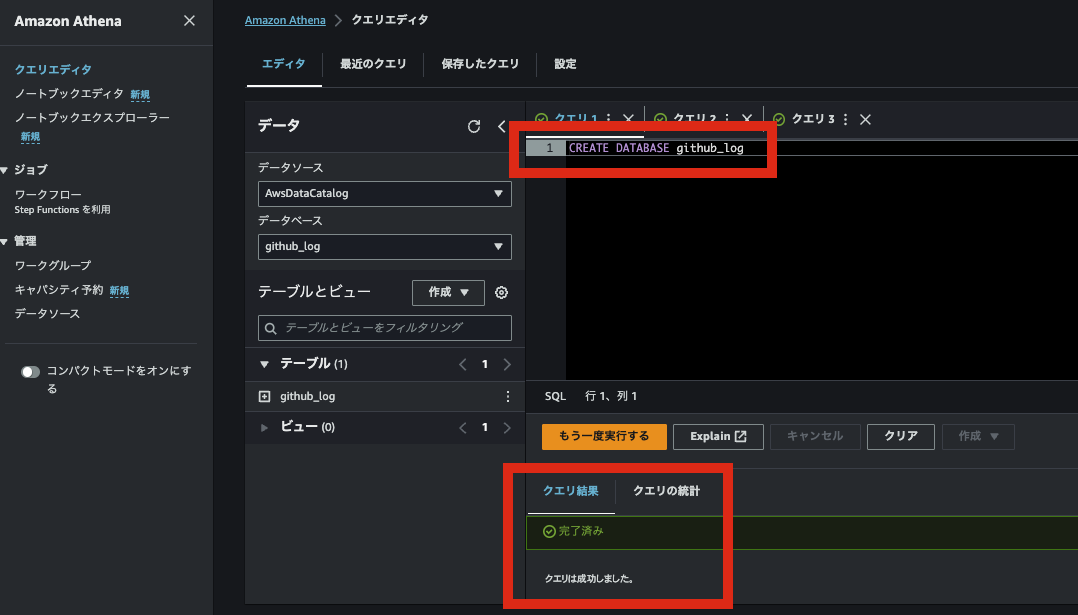
⑤ クエリ画面で作成したデータベースを選択します。
⑥ テーブルとビュー「作成」→「S3バケットデータ」と選択し、各設定をします。
今回は受信したログを列に分割せずそのまま1列として表示するようにしました。
テーブル名 :[任意のテーブル名]
データベース設定 :[クエリで作成したデータベース名]
データセット :s3://[ログが保存されているバケット名]/
テーブルタイプ :Apache Hive
ファイル形式 :カスタム区切りのテキストファイル
列の詳細 :任意(例:列名 data 、列のタイプ string)
⑦「テーブル」→「作成したテーブル名」のメニューから、「テーブルをプレビュー」を実行します。
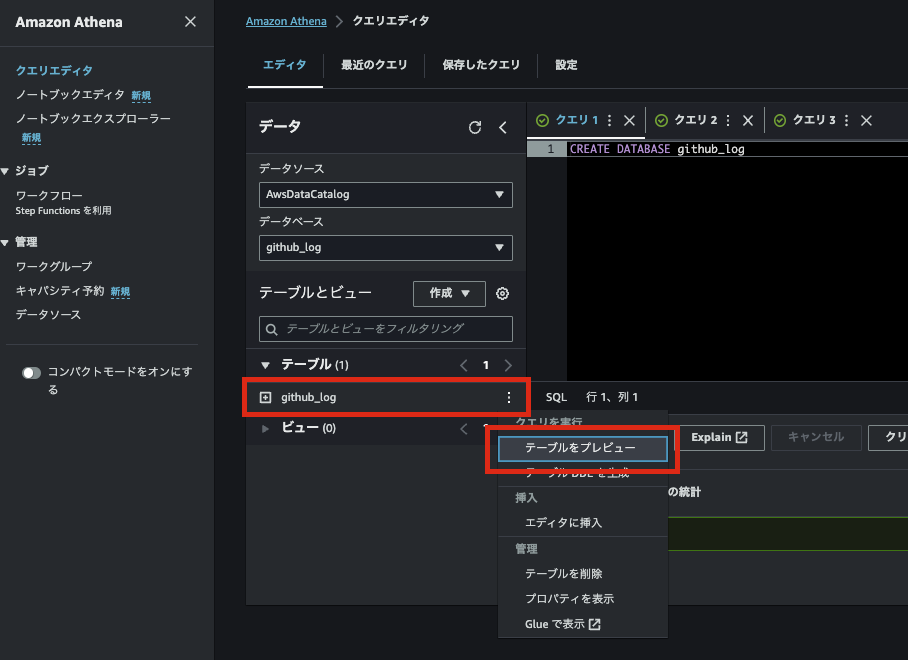
⑧ 結果を確認します。

⑨ 日付やリポジトリ名などでキーワード指定してログを確認してみます。

終わりに
ここまでAthenaでログが閲覧できることをご紹介していきました。 さらにここからクエリで検索・抽出・分析したり、実行結果の通知など幅が広がっていくと思います。 なお、Athenaはクエリでスキャンされたデータ量に対して課金されます。 課金を抑えるためには、テーブルをパーティション化してスキャン範囲を絞って実行することが推奨されます。 パーティション化の参考として、AWS公式ドキュメントをご紹介します。
また、GitHubではsyslogの他にauditlogもstreaming機能でS3へ転送できますので、Athenaで確認が可能です。